由於<div>標籤是用來群組其他元素來建立紀錄和欄位,所以爬取群組的<div>標籤就如同是在爬取多筆紀錄,今天我們就來使用Web Scraper爬取容器標籤吧~
本此練習網址為:https://fchart.github.io/test/ex5_01.html
瀏覽網頁後,開啟開發人員工具可以看到三層巢狀<div>標籤,<div id=”content”>標籤是最上層,在他之下有三個<div class="article lightbiue">和兩個<div class=”article”>子標籤,再下一層也是<div>標籤,最後才是<h2>標籤和<p>標籤。




在Web Scraper新增一個名為div_tag的網站地圖,準備爬取三個<div class=”artcicle lightbule”>標籤的客戶端網頁技術的<h2>標籤。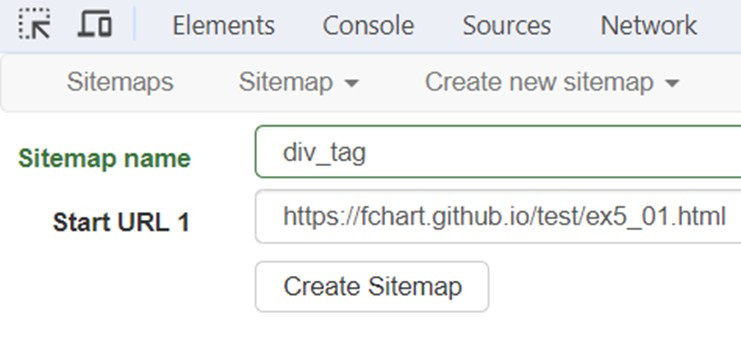
在_root根節點下新增名為items的節點,在Type欄選擇Element類型,選擇三個<div>標籤,可以取得CSS選擇器div.lightbule,由於有多個,所以要勾選Multipe,點選Save selector儲存。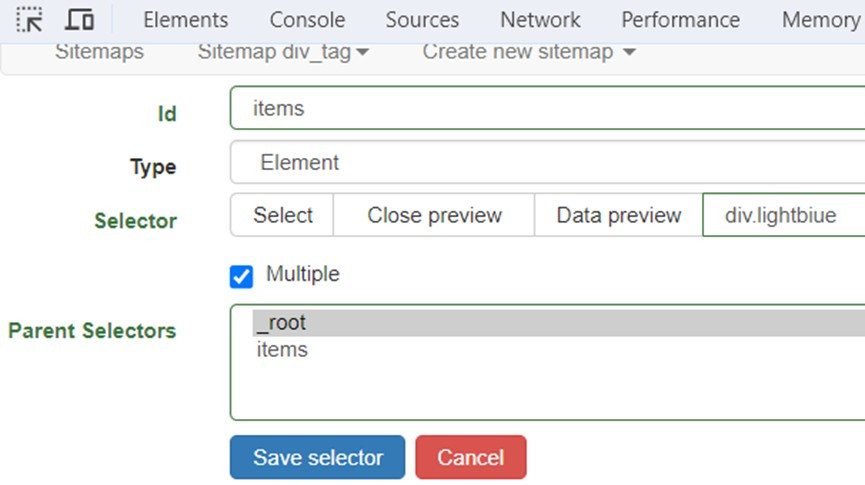
切換到_root/items路徑下,新增名為title的Text類型選擇器,選擇文字內容是HTML的<h2>標籤,可以取得CSS選擇器h2,點選Save selector儲存。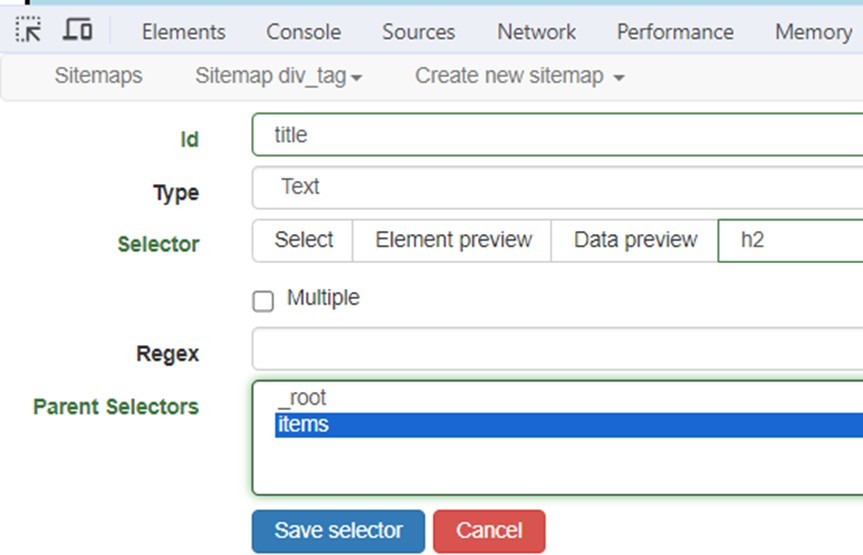
再新增一個名為note的Text類型選擇器,CSS選擇器是p。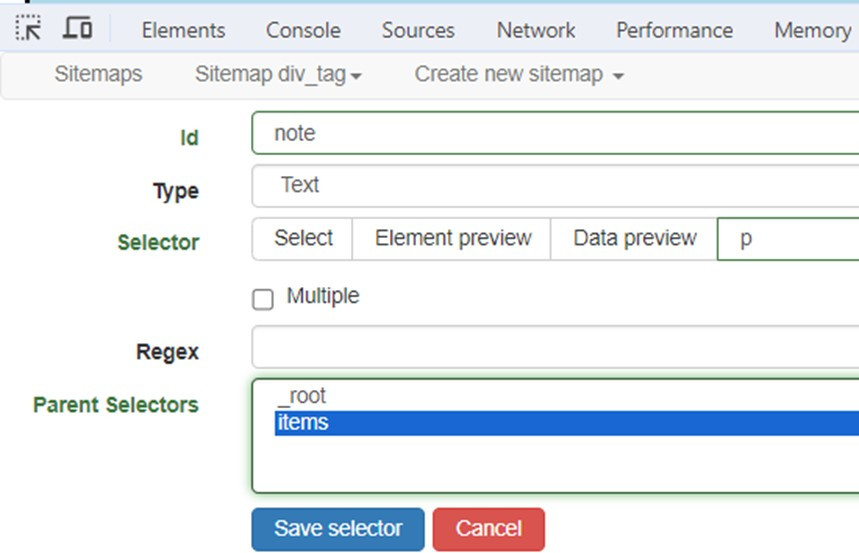
新增完成後,就完成了網站地圖的建立。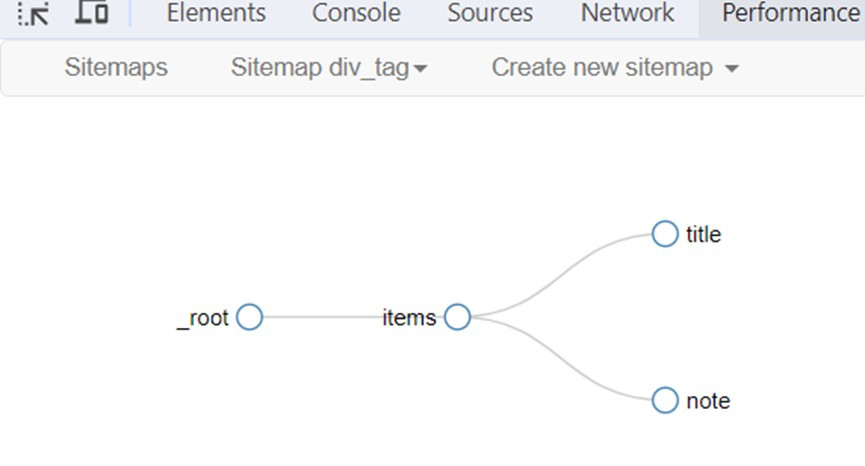
接下來使用Web Scraper執行網站地圖來爬取巢狀<div>標籤的資料,就可以看到擷取到的表格資料。
以Excel開啟匯成的CSV檔案:
這樣子就完成了!!
今天的分享就先到這邊,我們明天見~ 
參考書籍資料:文科生也可以輕鬆學習網路爬蟲
資料爬取練習來源同書籍

